
Deutsch-Chinesische Enzyklopädie, 德汉百科
 IT-Times
IT-Times
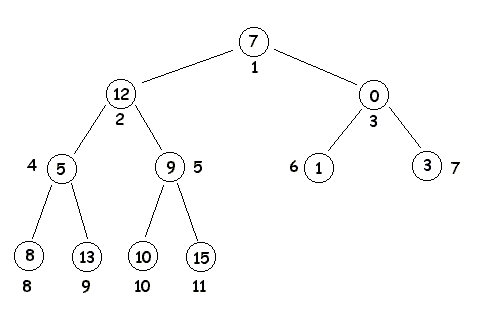
在计算机科学中,二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
二叉树的每个结点至多只有二棵子树(不存在度大于2的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第i层至多有 个结点;深度为k的二叉树至多有
个结点;深度为k的二叉树至多有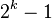 个结点;对任何一棵二叉树T,如果其终端结点数为
个结点;对任何一棵二叉树T,如果其终端结点数为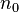 ,度为2的结点数为
,度为2的结点数为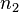 ,则
,则 。
。
一棵深度为k,且有个节点称之为满二叉树;深度为k,有n个节点的二叉树,当且仅当其每一个节点都与深度为k的满二叉树中,序号为1至n的节点对应时,称之为完全二叉树。
与树不同,树的结点个数至少为1,而二叉树的结点个数可以为0;树中结点的最大度数没有限制,而二叉树结点的最大度数为2;树的结点无左、右之分,而二叉树的结点有左、右之分。
![]()
 Education and Research
Education and Research
Education and Research
Education and Research
 *Important disciplines
*Important disciplines
 Important disciplines
Important disciplines
 Science and technology
Science and technology

Die Bioinformatik (englisch bioinformatics) ist eine interdisziplinäre Wissenschaft, die Probleme aus den Lebenswissenschaften mit theoretischen computergestützten Methoden löst. Sie hat zu grundlegenden Erkenntnissen der modernen Biologie und Medizin beigetragen. Bekanntheit in den Medien erreichte die Bioinformatik in erster Linie 2001 mit ihrem wesentlichen Beitrag zur Sequenzierung des menschlichen Genoms.
Bioinformatik ist ein weitgefächertes Forschungsgebiet, sowohl bei Problemstellungen als auch den angewandten Methoden. Wesentliche Gebiete der Bioinformatik sind die Verwaltung und Integration biologischer Daten, die Sequenzanalyse, die Strukturbioinformatik und die Analyse von Daten aus Hochdurchsatzmethoden (~omics). Da Bioinformatik unentbehrlich ist, um Daten in großem Maßstab zu analysieren, bildet sie einen wesentlichen Pfeiler der Systembiologie.
Der Bioinformatik wird im englischen Sprachraum oft die computational biology gegenübergestellt, die einen weiteren Bereich als die klassische Bioinformatik abdeckt, meist benutzt man beide Begriffe jedoch synonym.
生物信息学(英语:bioinformatics)利用应用数学、信息学、统计学和计算机科学的方法研究生物学的问题。生物信息学的研究材料和结果就是各种各样的生物学数据,其研究工具是计算机,研究方法包括对生物学数据的搜索(收集和筛选)、处理(编辑、整理、管理和显示)及利用(计算、模拟)。目前主要的研究方向有:序列比对、序列组装、基因识别、基因重组、蛋白质结构预测、基因表达、蛋白质反应的预测,以及创建进化模型。
生物学技术往往生成大量的嘈杂数据。与数据挖掘类似,生物信息学利用数学工具从大量数据中提取有用的生物学信息。生物信息学所要处理的典型问题包括:重新组装在霰弹枪测序法测序过程中被打散的DNA序列,从蛋白质的氨基酸序列预测蛋白质结构,利用mRNA微阵列或质谱仪的数据检验基因调控的假说。
某些人将计算生物学作为生物信息学的同义词处理;但是另外一些人认为计算生物学和生物信息学应当被当作不同的条目处理,因为生物信息学更侧重于生物学领域中计算方法的使用和发展,而计算生物学强调应用信息学技术对生物学领域中的假说进行检验,并尝试发展新的理论。
 Medical, Pharmaceutical, Rehabilitation
Medical, Pharmaceutical, Rehabilitation

Biomedizinische Datenwissenschaft ist ein multidisziplinäres Gebiet, das große Datenmengen nutzt, um biomedizinische Innovation und Entdeckung zu fördern. Biomedizinische Datenwissenschaft stützt sich auf verschiedene Bereiche, darunter Biostatistik, biomedizinische Informatik und maschinelles Lernen, mit dem Ziel, biologische und medizinische Daten zu verstehen. Sie kann als die Untersuchung und Anwendung der Datenwissenschaft zur Lösung biomedizinischer Probleme betrachtet werden. Moderne biomedizinische Datensätze weisen oft spezifische Merkmale auf, die ihre Analyse erschweren, darunter:
Große Anzahl von Merkmalen (manchmal Milliarden), die in der Regel viel größer sind als die Anzahl der Proben (in der Regel Dutzende oder Hunderte)
Verrauschte und fehlende Daten
Bedenken hinsichtlich des Datenschutzes (z. B. Vertraulichkeit elektronischer Gesundheitsdaten)
Erfordernis der Interpretierbarkeit durch Entscheidungsträger und Aufsichtsbehörden
Viele biomedizinische Datenforschungsprojekte wenden maschinelles Lernen auf solche Datensätze an, was die biomedizinische Datenforschung zu einem besonderen Bereich macht, auch wenn diese Merkmale auch in vielen anderen datenwissenschaftlichen Anwendungen zu finden sind.
 Companies
Companies
 Financial
Financial

Bitcoin ist die erste und die am Markt weltweit stärkste Kryptowährung auf Grundlage eines dezentral organisierten Buchungssystems.[7][8] Zahlungen werden kryptographisch legitimiert (digitale Signatur) und über ein Rechnernetz gleichberechtigter Computer (Peer-to-Peer) abgewickelt. Anders als im klassischen Bankensystem üblich, entspricht eine Transaktion mit Bitcoin dem Settlement zwischen den Beteiligten. Eigentumsnachweise an Bitcoin werden in persönlichen digitalen Brieftaschen (umgangssprachlich „Wallet“, engl.) gespeichert.[9] Der Kurs eines Bitcoin zu den gesetzlichen Zahlungsmitteln (Fiatgeld) folgt dem Grundsatz der Preisbildung an der Börse.