
漢德百科全書 | 汉德百科全书
 信息时代
信息时代

 游戏
游戏


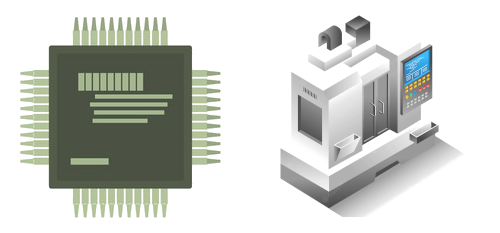
张量处理单元(英文:Tensor Processing Unit,简称:TPU),也称张量处理器,是 Google 开发的专用集成电路(ASIC),专门用于加速机器学习。自 2015 年起,谷歌就已经开始在内部使用 TPU,并于 2018 年将 TPU 提供给第三方使用,既将部分 TPU 作为其云基础架构的一部分,也将部分小型版本的 TPU 用于销售。
Tensor Processing Units (TPUs), auch Tensor-Prozessoren, sind anwendungsspezifische Chips um Anwendungen im Rahmen von maschinellem Lernen zu beschleunigen. TPUs werden vor allem genutzt, um Daten in künstlichen neuronalen Netzen, vgl. Deep Learning, zu verarbeiten.
Die von Google entwickelten TPUs wurden speziell für die Softwaresammlung TensorFlow[1] entworfen. TPUs sind die Basis für alle Google Services, welche maschinelles Lernen einsetzen, und wurden auch in den AlphaGo-Maschine-vs.-Mensch-Wettkämpfen mit einem der weltbesten Go-Spieler, Lee Sedol, zum Einsatz gebracht.[2]

 企业
企业

 财政金融
财政金融

Alipay (chinesisch 支付寶 / 支付宝, Pinyin zhīfùbǎo) ist ein chinesisches Onlinebezahlsystem der Alibaba Group betrieben durch die Ant Group. Alipay ist mit mehr als 520 Millionen[3] Nutzern weltweit die größte Payment- und Lifestyleplattform und hat mehr als 50 % Marktanteil im Online-Geschäft in der Volksrepublik China.

知识蒸馏(knowledge distillation)是人工智能领域的一项模型训练技术。该技术透过类似于教师—学生的方式,令规模较小、结构较为简单的人工智能模型从已经经过充足训练的大型、复杂模型身上学习其掌握的知识。该技术可以让小型简单模型快速有效学习到大型复杂模型透过漫长训练才能得到的结果,从而改善模型的效率、减少运算开销,因此亦被称为模型蒸馏(model distillation)。
In machine learning, knowledge distillation or model distillation is the process of transferring knowledge from a large model to a smaller one. While large models (such as very deep neural networks or ensembles of many models) have more knowledge capacity than small models, this capacity might not be fully utilized. It can be just as computationally expensive to evaluate a model even if it utilizes little of its knowledge capacity. Knowledge distillation transfers knowledge from a large model to a smaller one without loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device).
Model distillation is not to be confused with model compression, which describes methods to decrease the size of a large model itself, without training a new model. Model compression generally preserves the architecture and the nominal parameter count of the model, while decreasing the bits-per-parameter.
Knowledge distillation has been successfully used in several applications of machine learning such as object detection, acoustic models, and natural language processing. Recently, it has also been introduced to graph neural networks applicable to non-grid data.
