
漢德百科全書 | 汉德百科全书
 Companies
Companies

 California-CA
California-CA
 IT-Times
IT-Times
IT-Times
IT-Times
 Artificial Intelligence
IT-Times
Big Data
IT-Times
Android
IT-Times
Operating System
IT-Times
Search Engine
United States
Artificial Intelligence
IT-Times
Big Data
IT-Times
Android
IT-Times
Operating System
IT-Times
Search Engine
United States
 Science and technology
Global Innovators
Science and technology
Global Innovators

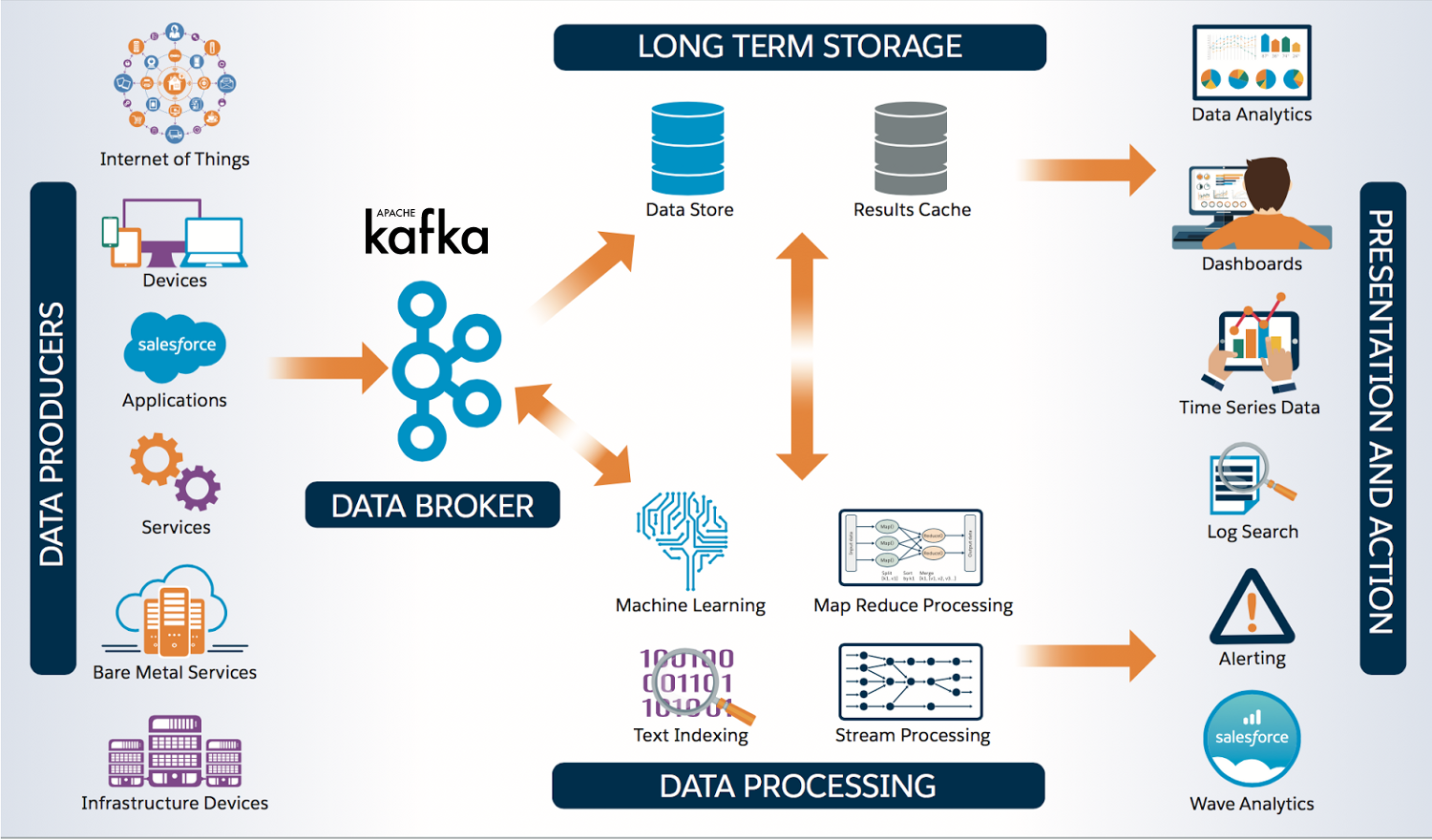
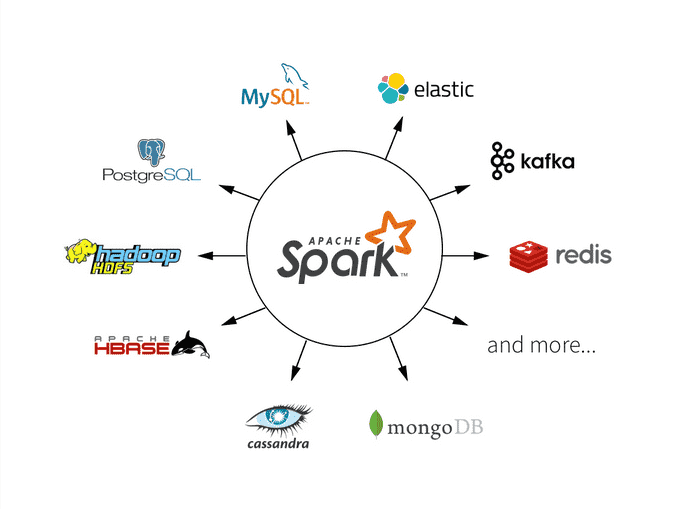
Apache Spark ist ein Framework für Cluster Computing, das im Rahmen eines Forschungsprojekts am AMPLab der University of California in Berkeley entstand und seit 2010 unter einer Open-Source-Lizenz öffentlich verfügbar ist. Seit 2013 wird das Projekt von der Apache Software Foundation weitergeführt[3] und ist dort seit 2014 als Top Level Project eingestuft[4].
 Education and Research
IT-Times
IT-Times
Artificial Intelligence
IT-Times
Big Data
IT-Times
Internet of Things
Education and Research
IT-Times
IT-Times
Artificial Intelligence
IT-Times
Big Data
IT-Times
Internet of Things

Edge Computing bezeichnet im Gegensatz zum Cloud Computing die dezentrale Datenverarbeitung am Rand des Netzwerks, der sogenannten Edge (engl. für Rand oder Kante). Fog Computing ist eine Form von Edge Computing. Oft werden auch Begriffe wie Local Cloud bzw. Cloudlet genutzt.
边缘运算(英语:Edge computing),是一种分散式运算的架构,将应用程式、数据资料与服务的运算,由网路中心节点,移往网路逻辑上的边缘节点来处理[1]。边缘运算将原本完全由中心节点处理大型服务加以分解,切割成更小与更容易管理的部份,分散到边缘节点去处理。边缘节点更接近于用户终端装置,可以加快资料的处理与传送速度,减少延迟。在这种架构下,资料的分析与知识的产生,更接近于数据资料的来源,因此更适合处理大数据。
 History
N 2000 - 2100 AD
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
HPC
Science and technology
History
N 2000 - 2100 AD
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
HPC
Science and technology

Big Data [ˈbɪɡ ˈdeɪtə] (von englisch big „groß“ und data „Daten“) bezeichnet Daten-Mengen, die zu groß, oder zu komplex sind, oder sich zu schnell ändern, um sie mit händischen und klassischen Methoden der Datenverarbeitung auszuwerten. Der Begriff "Big Data" unterliegt als Schlagwort derzeit einem kontinuierlichen Wandel; so wird mit Big Data ergänzend auch oft der Komplex der Technologien beschrieben, die zum Sammeln und Auswerten dieser Datenmengen verwendet werden.[1][2] Die gesammelten Daten können aus nahezu allen Quellen stammen: angefangen bei jeglicher elektronischer Kommunikation, über von Behörden und Firmen gesammelte Daten, bis hin zu den Aufzeichnungen verschiedenster Überwachungssysteme.[3] Big Data können so auch Bereiche abdecken, die bisher als privat galten. Der Wunsch der Industrie und bestimmter Behörden, möglichst umfassenden Zugriff auf diese Daten zu erhalten, sie besser analysieren zu können und die gewonnenen Erkenntnisse zu nutzen, gerät dabei zunehmend in Konflikt mit Persönlichkeitsrechten des Einzelnen.
 6G
Deep connectivity
6G
Holographic connectivity
6G
Intelligent connectivity
6G
Ubiquitous connectivity
History
N 2000 - 2100 AD
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse
Science and technology
Technology concepts
6G
Deep connectivity
6G
Holographic connectivity
6G
Intelligent connectivity
6G
Ubiquitous connectivity
History
N 2000 - 2100 AD
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse
Science and technology
Technology concepts
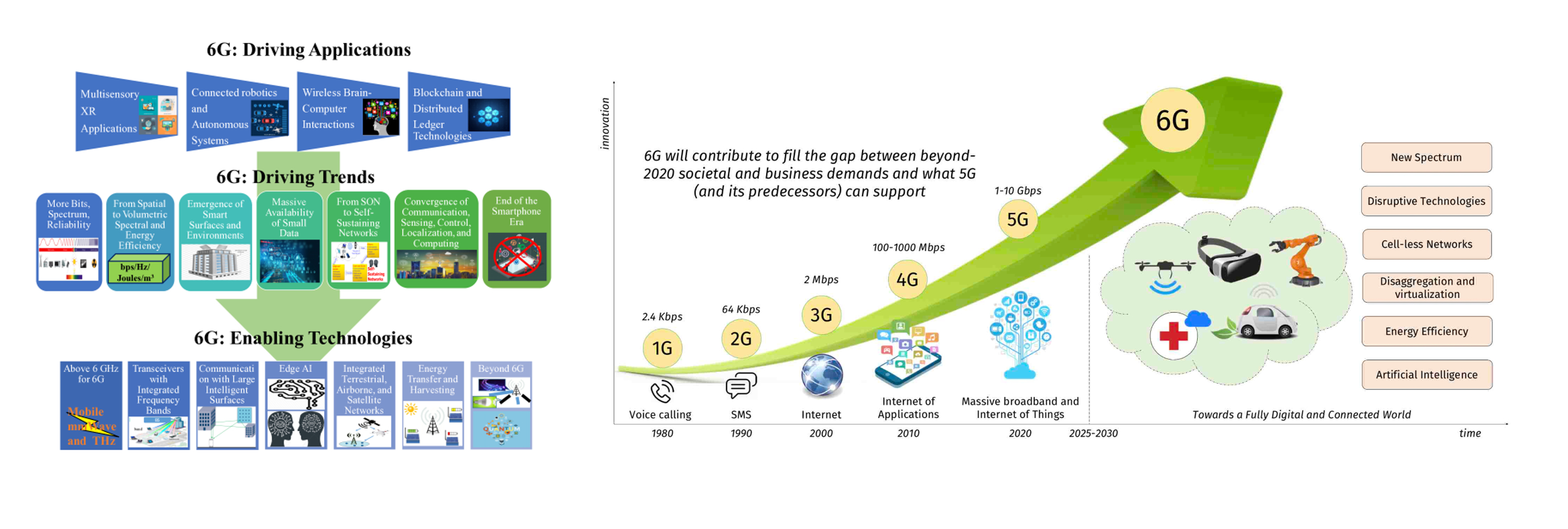


 Automobile
***Technology
History
N 2000 - 2100 AD
IT-Times
Big Data
IT-Times
Cloud Computing
IT-Times
Games industry
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
***Metaverse
Automobile
***Technology
History
N 2000 - 2100 AD
IT-Times
Big Data
IT-Times
Cloud Computing
IT-Times
Games industry
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
***Metaverse


 Aerospace
Aerospace



 Military, defense and equipment
Military, defense and equipment
 Ships and Nautics
Ships and Nautics
 Transport and traffic
Science and technology
Transport and traffic
Science and technology

 Financial
Financial
 Economy and trade
Economy and trade
 Automobile
***Technology
History
N 2000 - 2100 AD
IT-Times
Big Data
IT-Times
Cloud Computing
Science and technology
Technology concepts
Automobile
***Technology
History
N 2000 - 2100 AD
IT-Times
Big Data
IT-Times
Cloud Computing
Science and technology
Technology concepts
