
漢德百科全書 | 汉德百科全书

 California-CA
California-CA
 History
History
History
History
 N 2000 - 2100 AD
N 2000 - 2100 AD
 IT-Times
IT-Times
Artificial Intelligence
United States
IT-Times
IT-Times
Artificial Intelligence
United States
 Science and technology
Science and technology
Technology concepts
Science and technology
Science and technology
Technology concepts



循环神经网络(Recurrent neural network:RNN)是神经网络的一种。单纯的RNN因为无法处理随着递归,权重指数级爆炸或梯度消失问题,难以捕捉长期时间关联;而结合不同的LSTM可以很好解决这个问题。[1][2]
时间循环神经网络可以描述动态时间行为,因为和前馈神经网络(feedforward neural network)接受较特定结构的输入不同,RNN将状态在自身网络中循环传递,因此可以接受更广泛的时间序列结构输入。手写识别是最早成功利用RNN的研究结果。
Als rekurrente bzw. rückgekoppelte neuronale Netze bezeichnet man neuronale Netze, die sich im Gegensatz zu den Feedforward-Netzen durch Verbindungen von Neuronen einer Schicht zu Neuronen derselben oder einer vorangegangenen Schicht auszeichnen. Im Gehirn ist dies die bevorzugte Verschaltungsweise neuronaler Netze, insbesondere im Neocortex. In künstlichen neuronalen Netzen wird die rekurrente Verschaltung von Modellneuronen benutzt, um zeitlich codierte Informationen in den Daten zu entdecken.[1][2] Beispiele für solche rekurrenten neuronalen Netze sind das Elman-Netz, das Jordan-Netz, das Hopfield-Netz sowie das vollständig verschaltete neuronale Netz.


 Automobile
***Technology
Automobile
*Self-driving car
IT-Times
Internet of Things
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
IT-Times
Artificial Intelligence
Automobile
***Technology
Automobile
*Self-driving car
IT-Times
Internet of Things
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
IT-Times
Artificial Intelligence
 Life and Style
Life and Style
*E-Commerce
Life and Style
Life and Style
*E-Commerce
 Companies
*Big retail companies
United States
Companies
*Big retail companies
United States
 Washington-WA
Science and technology
Global Innovators
Washington-WA
Science and technology
Global Innovators


SageMaker ermöglicht es Entwicklern, beim Training und der Bereitstellung von Modellen für maschinelles Lernen auf verschiedenen Abstraktionsebenen zu arbeiten. Auf der höchsten Abstraktionsebene bietet SageMaker vortrainierte ML-Modelle, die so wie sie sind eingesetzt werden können. Darüber hinaus bietet SageMaker eine Reihe von integrierten ML-Algorithmen, die Entwickler auf ihren eigenen Daten trainieren können. Darüber hinaus bietet SageMaker verwaltete Instanzen von TensorFlow und Apache MXNet, in denen Entwickler ihre eigenen ML-Algorithmen von Grund auf neu erstellen können – unabhängig davon, welche Abstraktionsebene verwendet wird, kann ein Entwickler seine SageMaker-fähigen ML-Modelle mit anderen AWS-Diensten verbinden, wie z. B. der Amazon-DynamoDB-Datenbank für die strukturierte Datenspeicherung, AWS Batch für die Offline-Batchverarbeitung, oder Amazon Kinesis für die Echtzeitverarbeitung.
AI-Ran Alliance
Cloud Computing
PaaS
IAA Mobility
IAA Mobility
2025
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence


History
N 2000 - 2100 AD
IT-Times
CAD/CAE/CAM/EDA/PDM/PLM
IT-Times
CNC
IT-Times
CRM/EAM/ERP/SRM/SCM/HCM/QM/XM/WFM
IT-Times
Industrial Robot
IT-Times
PLC/DCS/FCS/SCADA/MES
IT-Times
Artificial Intelligence
United Kingdom
Science and technology
 Automobile
***Technology
California-CA
IT-Times
FPGA
IT-Times
Processing Units - CPU, GPU, NPU, APU, TPU, VPU, FPGA, QPU, IPU, PIC
IT-Times
IC
IT-Times
Motherboard
IT-Times
Semiconductor technology
IT-Times
Internet of Things
IT-Times
Games industry
IT-Times
PCI-SIG
IT-Times
MCU
IT-Times
Artificial Intelligence
Partner of the Paris 2024 organizing committee
Companies
*Big semiconductor manufacturer
United States
Science and technology
Global Innovators
Automobile
***Technology
California-CA
IT-Times
FPGA
IT-Times
Processing Units - CPU, GPU, NPU, APU, TPU, VPU, FPGA, QPU, IPU, PIC
IT-Times
IC
IT-Times
Motherboard
IT-Times
Semiconductor technology
IT-Times
Internet of Things
IT-Times
Games industry
IT-Times
PCI-SIG
IT-Times
MCU
IT-Times
Artificial Intelligence
Partner of the Paris 2024 organizing committee
Companies
*Big semiconductor manufacturer
United States
Science and technology
Global Innovators

Intel Corporation (von englisch Integrated electronics, deutsch integrierte Elektronik; NASDAQ-Küzel INTC) ist ein US-amerikanischer Halbleiterhersteller mit Hauptsitz im kalifornischen Santa Clara (Silicon Valley).
英特尔(英语:Intel Corporation)是世界上第二大的半导体公司[5],也是首家推出x86架构中央处理器(CPU)的公司,总部位于美国加利福尼亚州圣克拉拉。由罗伯特·诺伊斯、高登·摩尔、安迪·葛洛夫,以“集成电子”(Integrated Electronics)之名在1968年7月18日共同创办公司,将高阶芯片设计能力与领导业界的制造能力结合在一起。英特尔也有开发主板芯片组、网卡、闪存、绘图芯片(GPU),与对通信与运算相关的产品等。“Intel Inside”的广告标语,Pentium系列处理器以及与微软组成的“Wintel”联盟在1990年代间非常成功地打响英特尔的品牌名号。


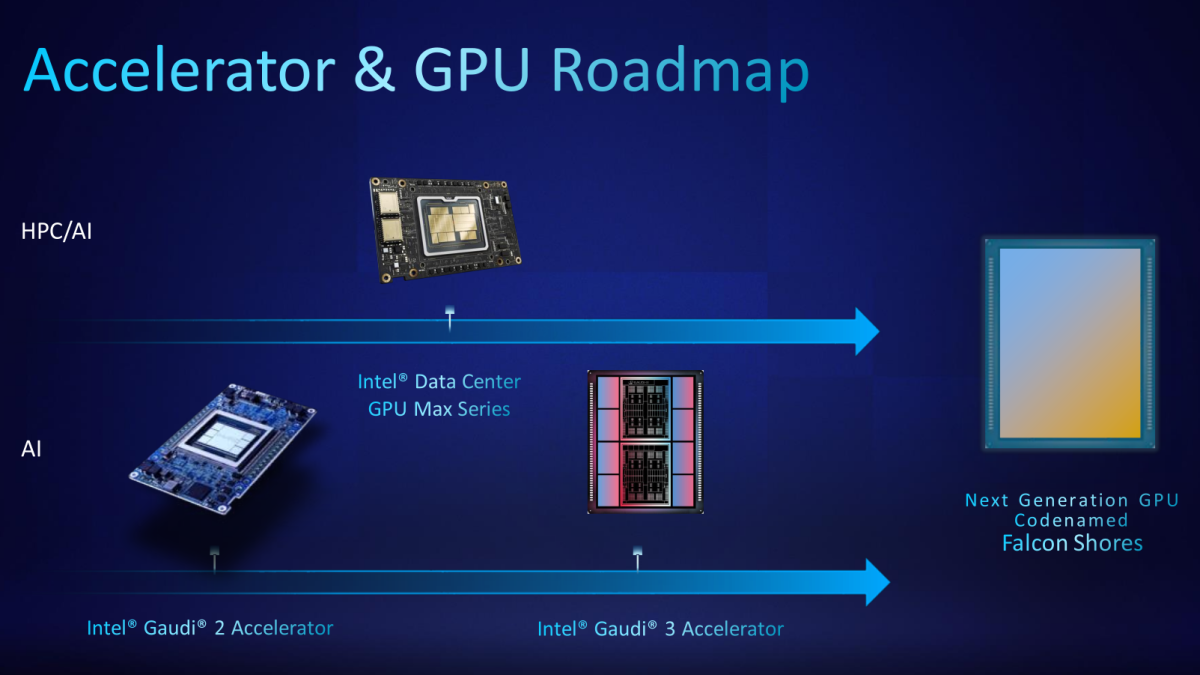 AI-Ran Alliance
Automobile
***Technology
Automobile
*Self-driving car
California-CA
Manufacturing and Innovation
IAA Mobility
IAA Mobility
2025
IT-Times
IC
IT-Times
Graphics card/Video card
IT-Times
Games industry
IT-Times
Semiconductor technology
IT-Times
Driver assistance systems
IT-Times
IT-Times
Artificial Intelligence
IT-Times
HPC
Life and Style
AI-Ran Alliance
Automobile
***Technology
Automobile
*Self-driving car
California-CA
Manufacturing and Innovation
IAA Mobility
IAA Mobility
2025
IT-Times
IC
IT-Times
Graphics card/Video card
IT-Times
Games industry
IT-Times
Semiconductor technology
IT-Times
Driver assistance systems
IT-Times
IT-Times
Artificial Intelligence
IT-Times
HPC
Life and Style
 Nvidia
Companies
*Big semiconductor manufacturer
United States
Nvidia
Companies
*Big semiconductor manufacturer
United States

Die Nvidia Corporation (Eigenschreibweise: NVIDIA,[3] Aussprache: /ɪnˈvɪdiə/, von lateinisch Invidia, Neid) ist einer der größten Entwickler von Grafikprozessoren und Chipsätzen für Personal Computer, Server und Spielkonsolen. Der Hauptsitz liegt in Santa Clara, Kalifornien. Die Nvidia Corporation besitzt keine eigenen Fertigungsstätten und arbeitet somit nach dem Fabless-Prinzip.
NVIDIA(Nvidia Corporation,/ɛnˈvɪdiə/;台湾与香港译为辉达,中国大陆译为英伟达),创立于1993年1月,是美国一家以设计和销售图形处理器(GPU)为主的无厂半导体公司,总部设在加利福尼亚州的圣克拉拉,位于硅谷的中心位置。NVIDIA最出名的产品线是为个人与游戏玩家所设计的GeForce系列,为专业CGI工作站而设计的Quadro系列,以及为服务器和高效运算而设计的Tesla系列,虽然起家于PC电脑的显卡业务,英伟达也曾涉及移动芯片Tegra的设计,但智能机市场对此响应不大,不过近年却利用这些研发经验,目前朝向人工智能和机器视觉的市场发展,也是图形处理器上重要的开发工具CUDA的发明者。

Einblicke in technologische Durchbrüche

Einheitliche KI-Architektur
Blackwell besteht aus 208 Milliarden Transistoren mit einem TSMC-4NP-Prozess, der den Erwartungen an die Führungsrolle von NVIDIA im Bereich beschleunigte Berechnungen entspricht, und seine Grafikprozessoren sind die leistungsstärksten Chips, die jemals entwickelt wurden. Die beiden Dies sind so groß wie möglich. Sie bieten die schnellste Kommunikationsleistung für KI-Operationen und maximieren gleichzeitig die Energieeffizienz. Sie sind über eine Chip-zu-Chip-NVHyperfuse-Schnittstelle miteinander verbunden, die 10 Terabyte pro Sekunde (TB/s) unterstützt. So wird eine transparente Einzel-GPU-Ansicht für alle Caches und Kommunikation möglich.
Generative KI-Engine
Außer der Transformer Engine-Technologie, die Training mit der Präzision von FP8 und FP16 beschleunigt, wird mit Blackwell die neue generative KI-Engine eingeführt. Die generative KI-Engine nutzt die angepasste Blackwell Tensor Core-Technologie zur Beschleunigung der Inferenz für generative KI und große Sprachmodelle (LLMs) mit neuen auf Präzision fokussierten Formaten, einschließlich Community-definierter Microscaling(MX)-Formate. Die Formate MXFP4, MXFP6, MXFP8 und MXINT8 der generativen KI-Engine bieten eine enorme Beschleunigung für moderne LLMs mit verbesserter Leistung durch geringeren Platzbedarf und mehr Durchsatz als FP8 und FP16.


Sichere KI
LLMs bergen ein enormes Potenzial für Unternehmen. Die Umsatzoptimierung, die Bereitstellung von Geschäftsinformationen und die Unterstützung bei der Erstellung generativer Inhalte sind nur einige der Vorteile. Doch die Einführung von LLMs kann für Unternehmen schwierig sein, da sie sie schulen müssen und dafür private Daten verwenden, die entweder Datenschutzbestimmungen unterliegen oder proprietäre Informationen enthalten, deren Offenlegung Risiken birgt. Blackwell umfasst NVIDIA Confidential Computing, das mit starker hardwarebasierter Sicherheit vertrauliche Daten und KI-Modelle vor unbefugtem Zugriff schützt.
Erfahren Sie mehr über Confidential Computing von NVIDIA
NVLink, NVSwitch und NVLink-Switch-Systeme
Um das volle Potenzial von Exascale-Computing und KI-Modellen mit Billionen Parametern auszuschöpfen, ist eine schnelle, nahtlose Kommunikation zwischen allen Grafikprozessoren innerhalb eines Server-Clusters erforderlich. Die fünfte Generation von NVLink ist eine Scale-up-Verbindung, die beschleunigte Leistung für KI-Modelle mit Billionen oder mehreren Billionen Parametern bietet.
Die vierte Generation von NVIDIA NVSwitch™ ermöglicht 130 TB/s GPU-Bandbreite in einer NVLink-Domäne mit 72 GPUs (NVL72) und bietet viermal mehr Bandbreiteneffizienz mit FP8-Unterstützung von NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™. Mithilfe von NVSwitch unterstützt das NVIDIA NVLink-Switch-System Cluster mit mehr als einem einzelnen Server bei denselben beeindruckenden Verbindungsgeschwindigkeiten von 1,8 TB/s. Multi-Server-Cluster mit NVLink skalieren die GPU-Kommunikation angepasst an die zunehmende Rechenleistung, sodass NVL72 den 9-fachen GPU-Durchsatz unterstützen kann als ein einzelnes System mit acht GPUs.
Weitere Informationen zu NVIDIA NVLink und NVSwitch


Dekomprimierungs-Engine
Bei Datenanalysen und Datenbank-Workflows wurden die Berechnungen traditionell auf CPUs durchgeführt. Beschleunigte Datenwissenschaft kann die Leistung von durchgängigen Analysen steigern, die Wertschöpfung beschleunigen und gleichzeitig die Kosten senken. Datenbanken, einschließlich Apache Spark, spielen im Bereich Datenanalyse eine entscheidende Rolle bei der Verarbeitung und Analyse großer Datenmengen.
Blackwells Dekomprimierungs-Engine und die Möglichkeit, auf riesige Mengen an Speicher der NVIDIA Grace™-CPU über eine High-Speed-Verbindung von 900 Gigabyte pro Sekunde (GB/s) bidirektionaler Bandbreite zuzugreifen, beschleunigen die gesamte Pipeline von Datenbankabfragen für höchste Leistung bei Datenanalysen und Datenwissenschaft. Dank der Unterstützung der neuesten Komprimierungsformate wie LZ4, Snappy und Deflate ist Blackwell 20-mal schneller als CPUs und 7-mal schneller als NVIDIA H100 Tensor Core-GPUs bei Abfrage-Benchmarks.
RAS-Engine für Zuverlässigkeit, Verfügbarkeit und Wartungsfreundlichkeit
Blackwell bietet intelligente Ausfallsicherheit mit einer dedizierten Engine für Zuverlässigkeit, Verfügbarkeit und Wartungsfreundlichkeit (Reliability, Availability, and Serviceability, RAS), um potenzielle Fehler frühzeitig zu identifizieren und Ausfallzeiten zu minimieren. Die KI-gestützten Funktionen für vorausschauendes Management von NVIDIA überwachen kontinuierlich den allgemeinen Zustand über Tausende von Datenpunkten von Hardware und Software, um die Ursachen für Ausfallzeiten und fehlende Effizienz vorherzusagen und zu eliminieren. Dadurch entsteht eine intelligente Ausfallsicherheit, die Zeit, Energie und Rechenkosten spart.
Die RAS-Engine von NVIDIA bietet detaillierte Diagnoseinformationen, mit denen Problembereiche identifiziert und Wartungsarbeiten geplant werden können. Die RAS-Engine reduziert die Durchlaufzeit, indem sie die Ursachen von Problemen schnell lokalisiert, und minimiert Ausfallzeiten durch eine effektive Problembehebung.
