
Deutsch-Chinesische Enzyklopädie, 德汉百科
IT-Times
Artificial Intelligence
***Metaverse*ACM Turing Award*Banking and financial services*IDE*IT security and data protection policy*Government3D-DruckAndroidAR/VRArtificial IntelligenceBig DataBlockchainCAD/CAE/CAM/EDA/PDM/PLMChat/Video Conferencing/PhoneCloud ComputingCMSCNCComputer Algebra System and MathematicsCRM/EAM/ERP/SRM/SCM/HCM/QM/XM/WFMCross platformData analysisDatabase management systemsPrinter/Photocopier/ScannereBookeCommercePower Engineering SoftwareDriver assistance systemsFPGAGames industryGaming ClubGraphics software and graphics tabletGraphics card/Video cardSemiconductor technologyHPCICIndustrial RobotInstant Messaging und VoIPInternet of ThingsLinux/UnixMainframeMCU MedicineMicrosoft WindowsMobile Networks Modernization of agricultureMotherboardMusic productionOperating SystemPayment SystemPCI-SIGPLC/DCS/FCS/SCADA/MES Precision Instrument/Medical Equipment/Research EquipmentProduction Engineering/Manufacturing TechnologiesProfessional media softwareProgramming language and frameworkQuantum ComputingRoot name serverSensorSmart phoneSocial networkStreaming MediaStream processorSearch Engine TCP/IP ProtocolsTuring AwardProcessing Units - CPU, GPU, APU, TPU, VPU, FPGA, QPU, IPU, PICVersion controlDistributed systemVirtualization

 IT-Times
IT-Times

Das MLPerf Training Die Benchmark-Suite misst die Geschwindigkeit, mit der verschiedene Systeme Modelle trainieren können, um eine bestimmte Qualitätsmetrik zu erfüllen. Die Benchmarks decken verschiedene Bereiche ab, darunter Vision, Sprache und Handel, und verwenden unterschiedliche Datensätze und Qualitätsziele.


制造创新国家网络计划/Manufacturing USA
神经信息处理系统


诺基亚
1865, Nokia Oyj [ˈnɔkiɑ] bzw. Nokia Corporation ist ein Telekommunikationskonzern mit Hauptsitz im finnischen Espoo, der weltweit Mobile-, Festnetz- und Cloud-Netzwerklösungen anbietet.

英偉達 英伟达 Blackwell
Nvidia Blackwell besteht aus 208 Milliarden Transistoren mit einem TSMC-4NP-Prozess, der den Erwartungen an die Führungsrolle von NVIDIA im Bereich beschleunigte Berechnungen entspricht, und seine Grafikprozessoren sind die leistungsstärksten Chips, die jemals entwickelt wurden. Die beiden Dies sind so groß wie möglich. Sie bieten die schnellste Kommunikationsleistung für KI-Operationen und maximieren gleichzeitig die Energieeffizienz.

英偉達 英伟达
Die Nvidia Corporation (Eigenschreibweise: NVIDIA, Aussprache: /ɪnˈvɪdiə/, von lateinisch Invidia, Neid) ist einer der größten Entwickler von Grafikprozessoren und Chipsätzen für Personal Computer, Server und Spielkonsolen. Der Hauptsitz liegt in Santa Clara, Kalifornien. Die Nvidia Corporation besitzt keine eigenen Fertigungsstätten und arbeitet somit nach dem Fabless-Prinzip.

Die nächste Grenze der KI ist die physische KI. NVIDIA Cosmos™ - eine Plattform mit hochmodernen generativen Weltmodellen, fortschrittlichen Tokenizern, Guardrails und einer beschleunigten Datenverarbeitungs- und -kuratierungspipeline - beschleunigt die Entwicklung von Systemen mit physischer KI wie Robotern und autonomen Fahrzeugen.
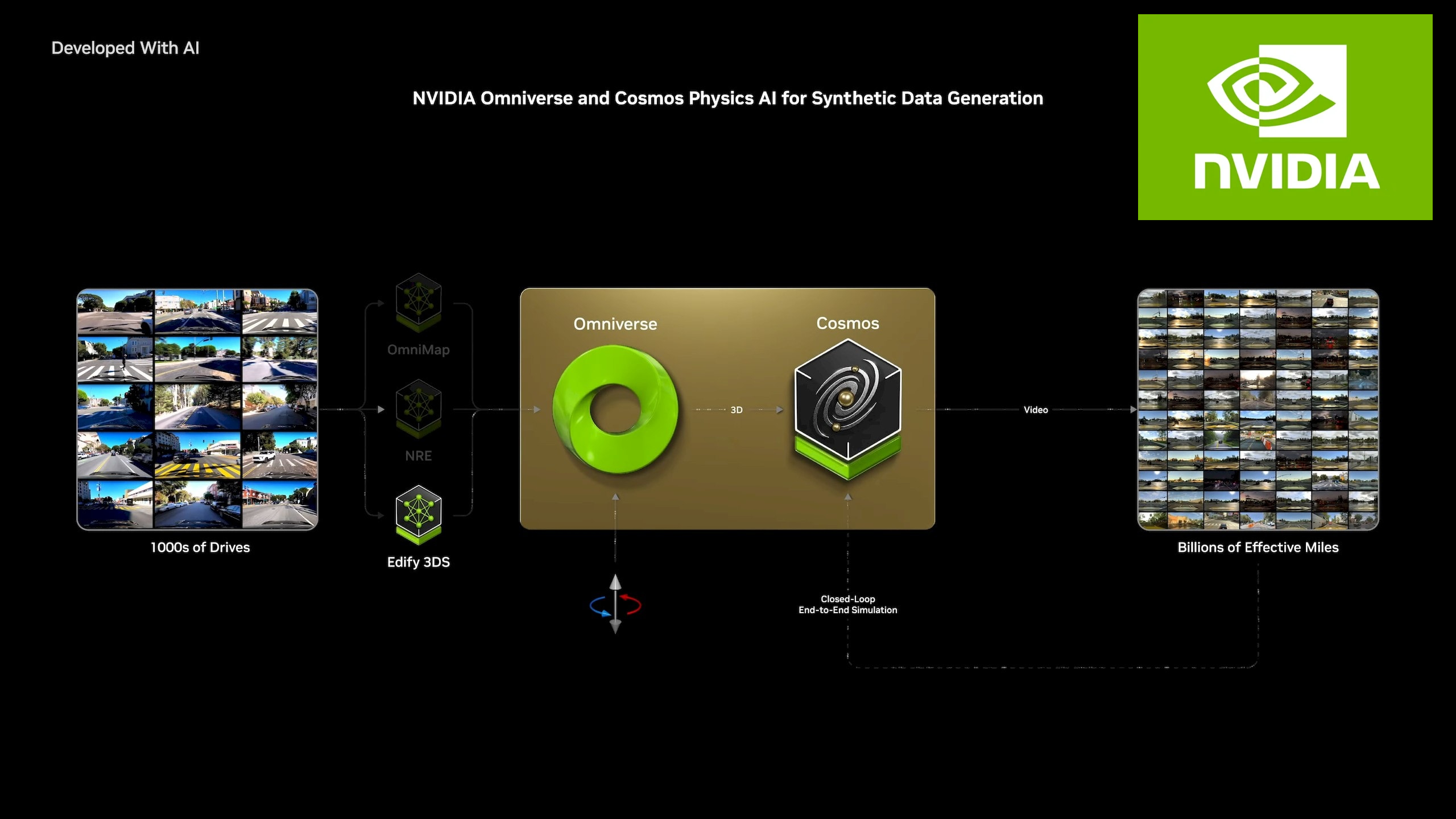


 Automobile
Automobile
英偉達雷神驅動 英伟达雷神驱动
NVIDIA DRIVE Thor donnert in die nächste Generation des autonomen Fahrzeug-Computings, indem es die Effizienz und Leistung blitzschnell verbessert DRIVE Thor ist das Nachfolgemodell von NVIDIA DRIVE Orin und umfasst die neueste Rechentechnologie, um die Einführung von Smart-Vehicle-Technologien in der Industrie zu beschleunigen, wobei der Schwerpunkt auf den Modellen der Automobilhersteller für 2025 liegt.

英偉達 英伟达 GB200/Grace Blackwell 200
Nvidia hat im Rahmen seiner hauseigenen KI-Entwicklerkonferenz GTC 2024 neben der neuen Dual-Die-GPU Nvidia B200 ("Blackwell") auch den auf dieser Grafiklösung basierenden riesigen Superchip GB200 ("Grace Blackwell") mit Grace-CPU für den hauseigenen NVL72-Supercomputer sowie Kundenlösungen vorgestellt.

英偉達 英伟达 GB200 NVL72
Der GB200 NVL72 verbindet 36 Grace-CPUs und 72 Blackwell-GPUs in einem Rack-Maßstab. Bei dem GB200 NVL72 handelt es sich um eine Rack-Lösung mit Flüssigkeitskühlung und einer NVLink-Domäne mit 72 Grafikprozessoren, die als einzelner riesiger Grafikprozessor funktioniert und 30-mal schnellere Echtzeit-Inferenz für LLMs mit Billionen Parametern bietet.
