
Deutsch-Chinesische Enzyklopädie, 德汉百科



 Automobile
Automobile
 ***Technology
***Technology
 History
N 2000 - 2100 AD
History
N 2000 - 2100 AD
 IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse
IT-Times
Artificial Intelligence
IT-Times
Cloud Computing
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse


 Aerospace
Aerospace



 Military, defense and equipment
Military, defense and equipment
 Ships and Nautics
Ships and Nautics
 Transport and traffic
Transport and traffic
 Science and technology
Science and technology
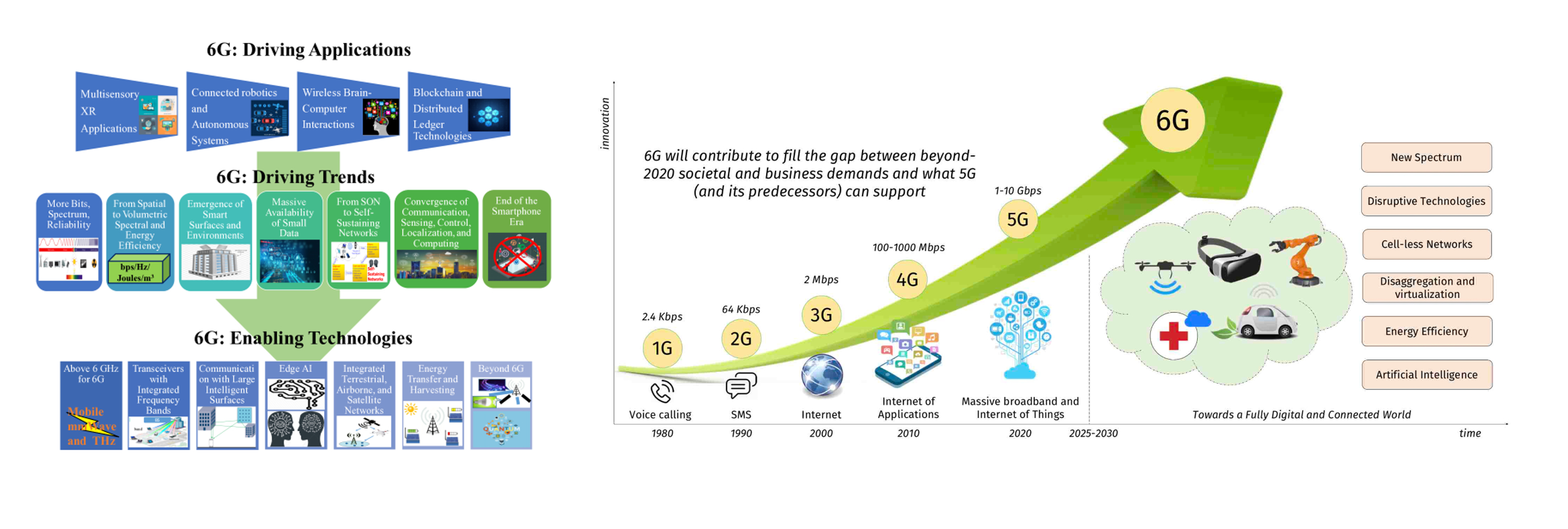
 6G
Holographic connectivity
6G
Deep connectivity
6G
Intelligent connectivity
6G
Ubiquitous connectivity
History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse
Science and technology
Technology concepts
6G
Holographic connectivity
6G
Deep connectivity
6G
Intelligent connectivity
6G
Ubiquitous connectivity
History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence
IT-Times
Internet of Things
IT-Times
Mobile Networks
IT-Times
Games industry
IT-Times
***Metaverse
Science and technology
Technology concepts
 Companies
Companies
 California-CA
IT-Times
IT-Times
Artificial Intelligence
IT-Times
Android
IT-Times
Operating System
IT-Times
Search Engine
IT-Times
Big Data
United States
Science and technology
Global Innovators
California-CA
IT-Times
IT-Times
Artificial Intelligence
IT-Times
Android
IT-Times
Operating System
IT-Times
Search Engine
IT-Times
Big Data
United States
Science and technology
Global Innovators


Apache® Spark™ 是一种开放源码计算框架,它使用内存内处理技术,与当今市场中的其他技术相比,可以使分析应用的运行速度提升 100 倍。Apache Spark 由加州大学伯克利分校的 AMPLab 开发,旨在通过深层次的智能,帮助降低数据交互的复杂性,提高处理速度,增强任务关键型应用。
Apache Spark 适用于为数众多的环境,以易于使用,能够创建算法从复杂数据中提取洞察而闻名。Spark 在 2014 年升级成为顶级 Apache 项目,并继续扩展。
IBM 对 Apache Spark 项目作出承诺,投资于以设计为主导的创新和大规模的培训计划,促进开放源码创新,将智能加速融入每一个应用。
History
HPC
History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence
IT-Times
IT-Times
HPC
Science and technology

大数据(英语:Big data[1][2]或Megadata),或称巨量数据、海量数据、大资料,指的是所涉及的数据量规模巨大到无法通过人工,在合理时间内达到截取、管理、处理、并整理成为人类所能解读的信息[3][4]。在总数据量相同的情况下,与个别分析独立的小型数据集(data set)相比,将各个小型数据集合并后进行分析可得出许多额外的信息和数据关系性,可用来察觉商业趋势、判定研究质量、避免疾病扩散、打击犯罪或测定实时交通路况等;这样的用途正是大型数据集盛行的原因[5][6][7]。
截至2012年,技术上可在合理时间内分析处理的数据集大小单位为艾字节(exabytes)[8]。在许多领域,由于数据集过度庞大,科学家经常在分析处理上遭遇限制和阻碍;这些领域包括气象学、基因组学[9]、神经网络体学、复杂的物理模拟[10],以及生物和环境研究[11]。这样的限制也对网络搜索、金融与经济信息学造成影响。数据集大小增长的部分原因来自于信息持续从各种来源被广泛收集,这些来源包括搭载传感设备的移动设备、高空传感科技(遥感)、软件记录、相机、麦克风、无线射频辨识(RFID)和无线传感网络。自1980年代起,现代科技可存储数据的容量每40个月即增加一倍[12];截至2012年,全世界每天产生2.5艾字节(2.5×1018)的数据[13]。
大数据几乎无法使用大多数的数据库管理系统处理,而必须使用“在数十、数百甚至数千台服务器上同时平行运行的软件”[14]。大数据的定义取决于持有数据组的机构之能力,以及其平常用来处理分析数据的软件之能力。“对某些组织来说,第一次面对数百GB的数据集可能让他们需要重新思考数据管理的选项。对于其他组织来说,数据集可能需要达到数十或数百兆字节才会对他们造成困扰。”[15]
 History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Big Data
Science and technology
Technology concepts
History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Big Data
Science and technology
Technology concepts
 History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence
IT-Times
Big Data
IT-Times
***Metaverse
Science and technology
Technology concepts
History
N 2000 - 2100 AD
IT-Times
Cloud Computing
IT-Times
Artificial Intelligence
IT-Times
Big Data
IT-Times
***Metaverse
Science and technology
Technology concepts

云计算(英语:Cloud Computing),是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备。
云计算是继1980年代大型计算机到客户端-服务器的大转变之后的又一种巨变。用户不再需要了解“云”中基础设施的细节,不必具有相应的专业知识,也无需直接进行控制。[1]云计算描述了一种基于互联网的新的IT服务增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展而且经常是虚拟化的资源。[2][3]
在“软件即服务(SaaS)”的服务模式当中,用户能够访问服务软件及数据。服务提供者则维护基础设施及平台以维持服务正常运作。SaaS常被称为“随选软件”,并且通常是基于使用时数来收费,有时也会有采用订阅制的服务。
推广者认为,SaaS使得企业能够借由外包硬件、软件维护及支持服务给服务提供者来降低IT营运费用。另外,由于应用程序是集中供应的,更新可以即时的发布,无需用户手动更新或是安装新的软件。SaaS的缺陷在于用户的数据是存放在服务提供者的服务器之上,使得服务提供者有能力对这些数据进行未经授权的访问。
用户通过浏览器、桌面应用程序或是移动应用程序来访问云的服务。推广者认为云计算使得企业能够更迅速的部署应用程序,并降低管理的复杂度及维护成本,及允许IT资源的迅速重新分配以因应企业需求的快速改变。
云计算依赖资源的共享以达成规模经济,类似基础设施(如电力网)。服务提供者集成大量的资源供多个用户使用,用户可以轻易的请求(租借)更多资源,并随时调整使用量,将不需要的资源释放回整个架构,因此用户不需要因为短暂尖峰的需求就购买大量的资源,仅需提升租借量,需求降低时便退租。服务提供者得以将目前无人租用的资源重新租给其他用户,甚至依照整体的需求量调整租金。
Automobile
***Technology
History
N 2000 - 2100 AD
IT-Times
Technology concepts
IT-Times
Big Data
IT-Times
Cloud Computing
Science and technology
Technology concepts
